

728x90
준비
해당 예제는 아래 링크에 있는 에셋을 다운로드하여, 최신 ML-Agents 버전에 맞게 프로젝트를 수정하고 중요한 포인트를 학습하고 예제를 확장하는 방식으로 진행하겠습니다.
Unity Learn | Karting Microgame | URP | 템플릿 | Unity Asset Store
Use the Unity Learn | Karting Microgame | URP from Unity Technologies for your next project. Find this & other useful 템플릿 on the Unity Asset Store.
assetstore.unity.com
시작
- 프로젝트에 해당 에셋을 임포트 해줍니다.

- 해당 프로젝트를 열어 보면 ML Agents 버전이 낮은걸 확인 할 수 있습니다. 해당 버전을 최신 버전으로 올려 줍니다.

- ML Agents 버전을 올려주면 아래와 같이 오류가 뜹니다. 해당 오류는 패키지 충돌로 충돌이 나는 패키지를 제거 해주면 됩니다.

- 문제를 일으키는 Barracuda 패키지를 제거 하면 됩니다.

- 추가로 Cinemachine 업데이트로 해당 오류가 뜰 경우 아래와 같이 수정 해 주세요.


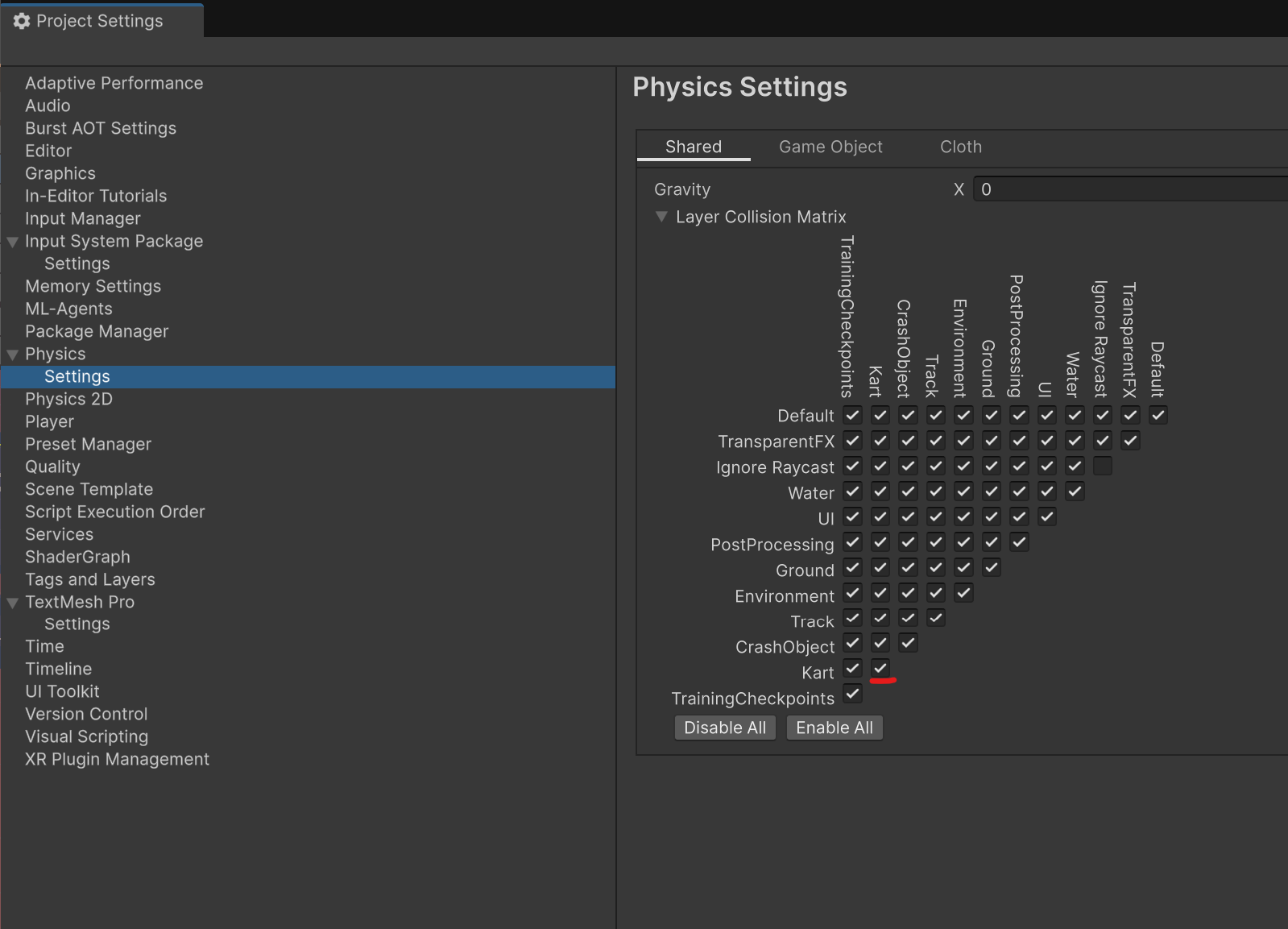
- 카트끼리 충돌하는걸 원하면 밑에 표시한 체크 박스 체크해 주세요.
훈련
- 훈련에 앞서 해당 프로젝트에 훈련 Config 파일에 버전이 낮아 오류가 발생합니다. 아래를 참고해 수정해주시면 됩니다.
- 주의 : 해당 학습 파일은 max_steps 이 굉장히 많습니다. 적절히 조절해서 사용해 주세요.
더보기
---
behaviors:
ArcadeDriver:
trainer_type: poca
hyperparameters:
batch_size: 512
buffer_size: 10240
beta: 0.005
epsilon: 0.2
lambd: 0.95
learning_rate: 0.0002
learning_rate_schedule: linear
network_settings:
hidden_units: 128
normalize: false
num_epoch: 3
num_layers: 2
vis_encode_type: simple
memory:
memory_size: 256
sequence_length: 64
reward_signals:
extrinsic:
strength: 1
gamma: 0.99
max_steps: 50000000000
time_horizon: 64
summary_freq: 1000
4x4Driver:
trainer_type: poca
hyperparameters:
batch_size: 512
buffer_size: 10240
beta: 0.0005
epsilon: 0.2
lambd: 0.95
learning_rate: 0.0003
learning_rate_schedule: linear
network_settings:
hidden_units: 128
normalize: false
num_epoch: 3
num_layers: 2
vis_encode_type: simple
memory:
memory_size: 256
sequence_length: 64
reward_signals:
extrinsic:
strength: 1
gamma: 0.99
max_steps: 50000000000
time_horizon: 64
summary_freq: 1000
MuscleDriver:
trainer_type: poca
hyperparameters:
batch_size: 512
buffer_size: 10240
beta: 0.0005
epsilon: 0.2
lambd: 0.95
learning_rate: 0.0003
learning_rate_schedule: linear
network_settings:
hidden_units: 128
normalize: false
num_epoch: 3
num_layers: 2
vis_encode_type: simple
memory:
memory_size: 256
sequence_length: 64
reward_signals:
extrinsic:
strength: 1
gamma: 0.99
max_steps: 50000000000
time_horizon: 64
summary_freq: 1000
RoadsterDriver:
trainer_type: poca
hyperparameters:
batch_size: 512
buffer_size: 10240
beta: 0.0005
epsilon: 0.2
lambd: 0.95
learning_rate: 0.0002
learning_rate_schedule: linear
network_settings:
hidden_units: 128
normalize: false
num_epoch: 3
num_layers: 2
vis_encode_type: simple
memory:
memory_size: 256
sequence_length: 64
reward_signals:
extrinsic:
strength: 1
gamma: 0.99
max_steps: 50000000000
time_horizon: 64
summary_freq: 1000
- 훈련을 하기 위해서는 훈련 전용 씬이 필요한데 이 패키지에 들어 있습니다. 아래 씬을 쓰시면 됩니다.
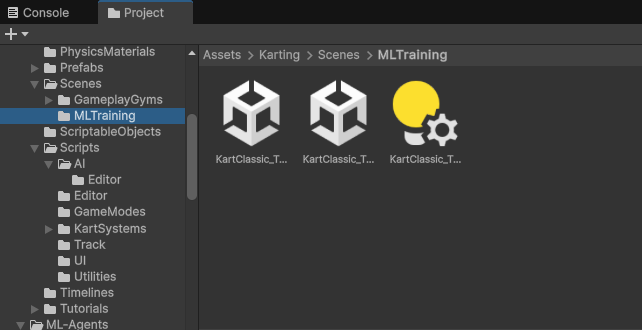
- 씬을 처음 여시면 빈 공간에 에이전트 하나 만 있습니다. 바로 훈련을 하셔도 되고 아래 처럼 몇개를 더 추가 해서 학습을 돌려도 됩니다.


- 추가 카트 같은 경우는 Karting -> AddOns 에 있으니 참고 바랍니다.

- 카트 추가를 하실 때 고려할 사항이 있습니다. 에이전트를 훈련 모드로 바꿔 주는 거랑 체크 포인트를 추가 해주셔야 합니다.
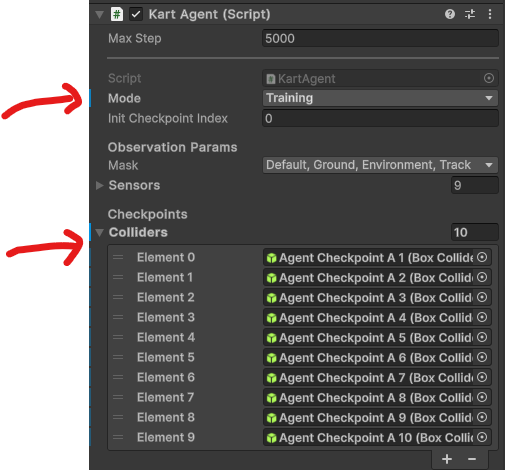
- 체크 포인트 같은 경우는 씬에 Training Set 아래 CheckPoint 들이 있으므로 참고 해주세요. 추가로 단순 레이어만 바꾼 콜라이더 이므로 커스텀을 하셔서 쓰셔도 됩니다.
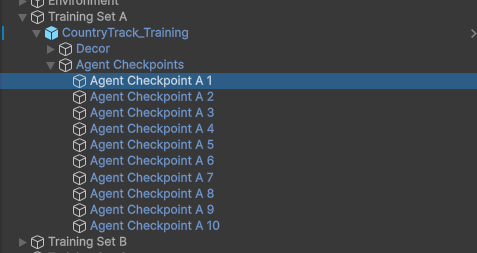
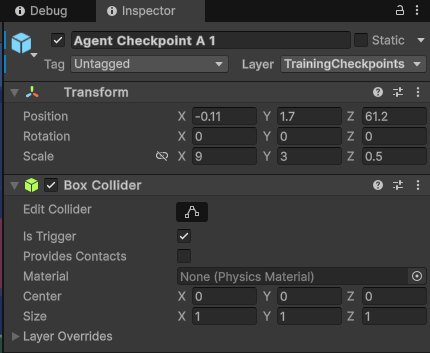
- 세팅 후 학습을 돌려 주시면 됩니다. 훈련 아이디는 아무 거나 넣으시면 됩니다.
mlagents-learn kart_mg_trainer_config.yaml --run-id=001
주의점
학습 중 이상 현상
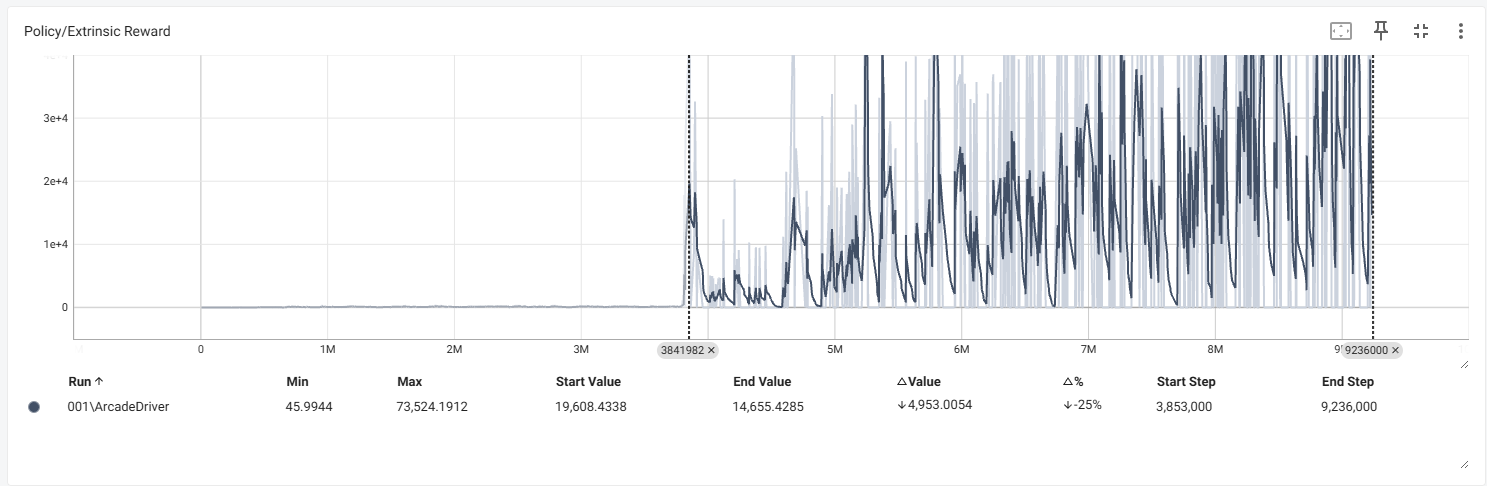
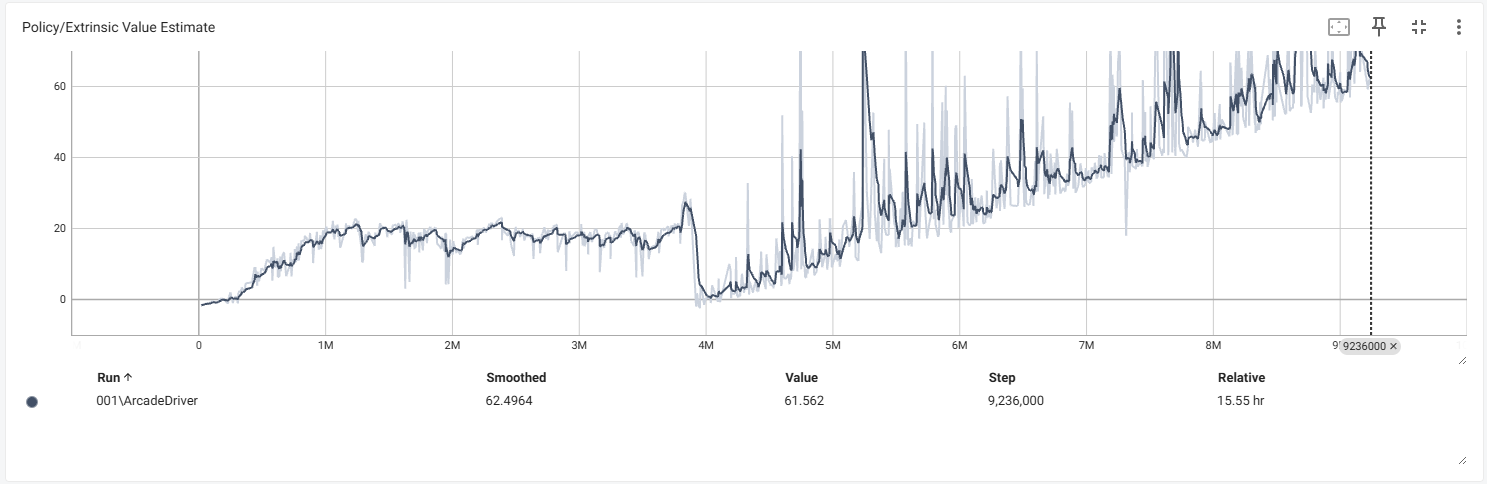
- 학습 하는 과정에서 에이전트가 맵 밖을 나가 밑으로 빠지는등 예상을 벗어나는 행동을 했을때는 학습이 이상하게 진행이 됩니다.
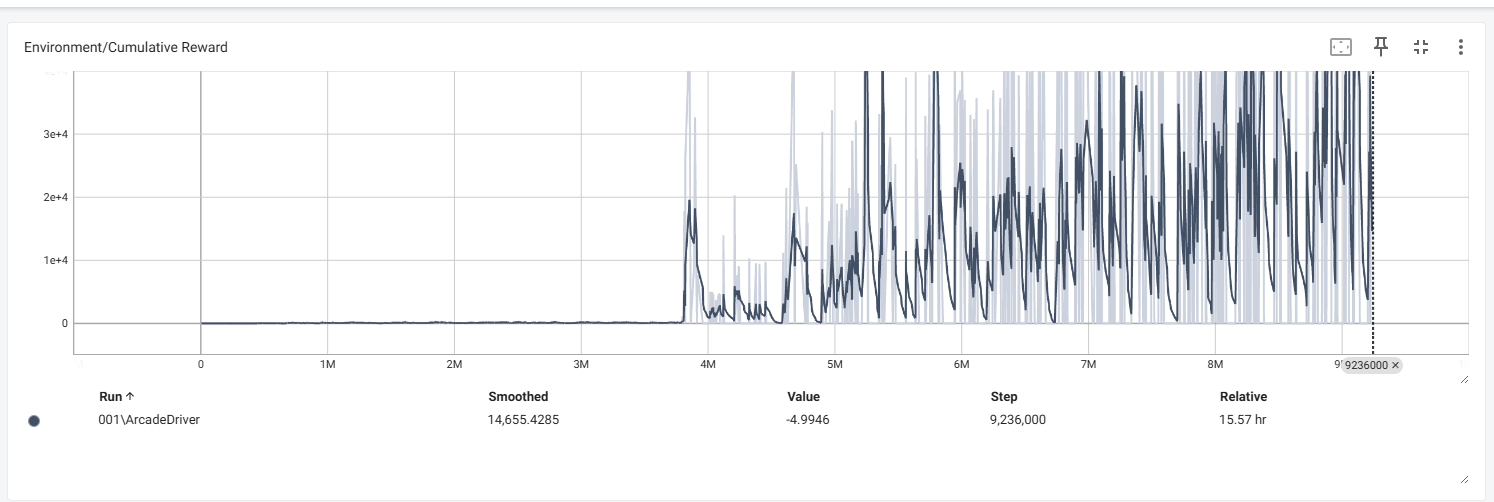
- 손실 부분을 보면 대략 400만 스텝 부터 뭔가 이상해지기 시작했습니다. 학습중 에이전트 하나가 트랙을 탈주해 밑으로 계속 떨어지는 시점이 대략 저쯤인거 같네요.
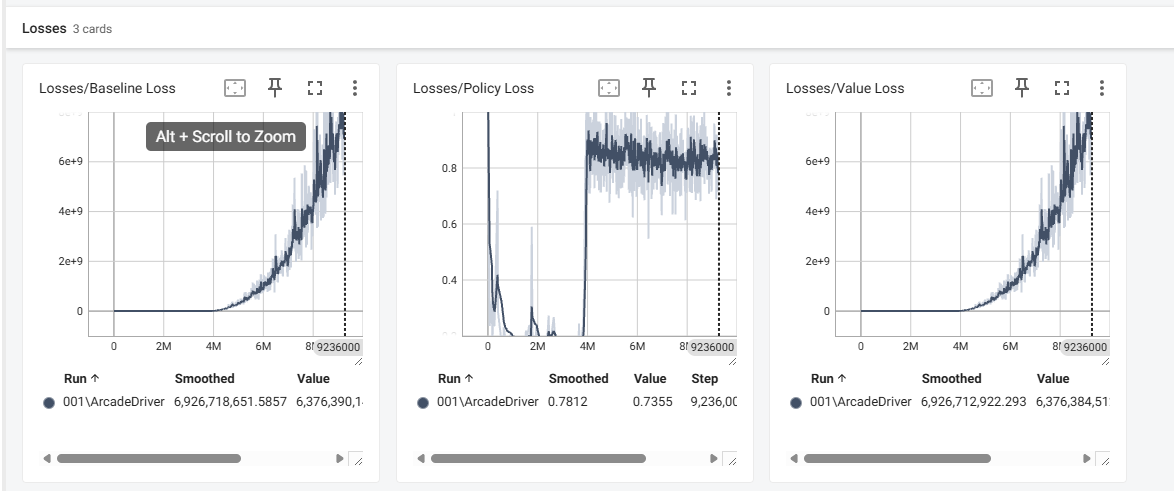
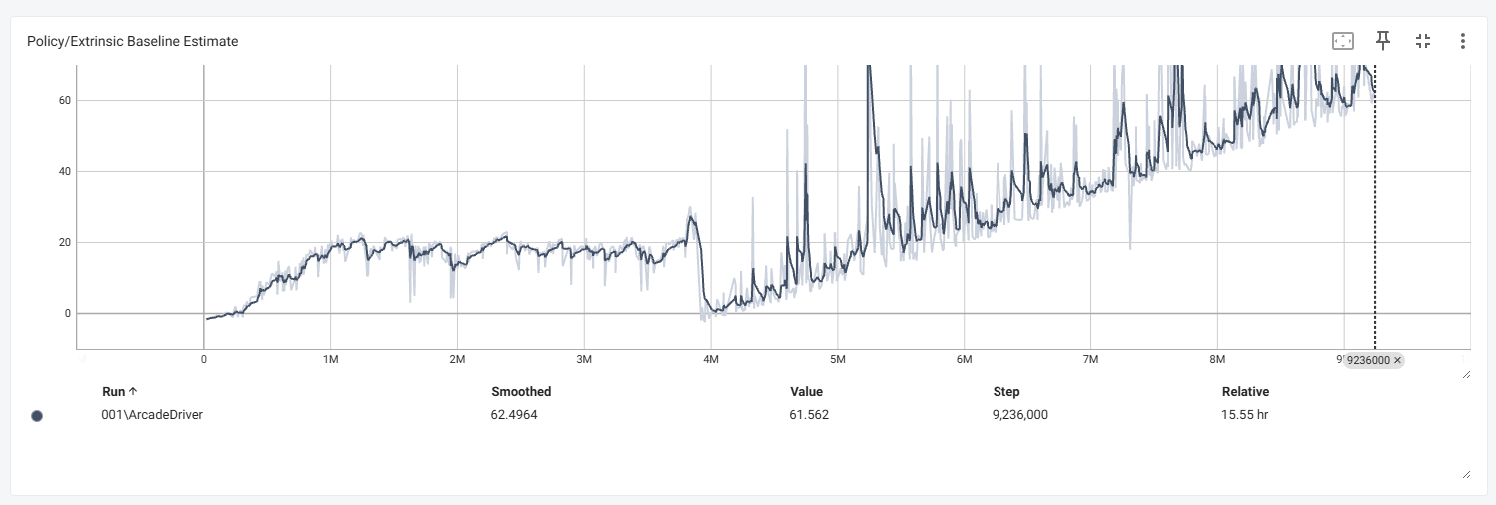
- 정책 부분에서 보상관련 내용들이 400만 부터 이상해 지는 것을 확인 할 수 있습니다.
확장
- 추가 프로젝트 확장에 관련된 내용은 추가 페이지를 통해 학습을 진행 하겠습니다.
728x90